

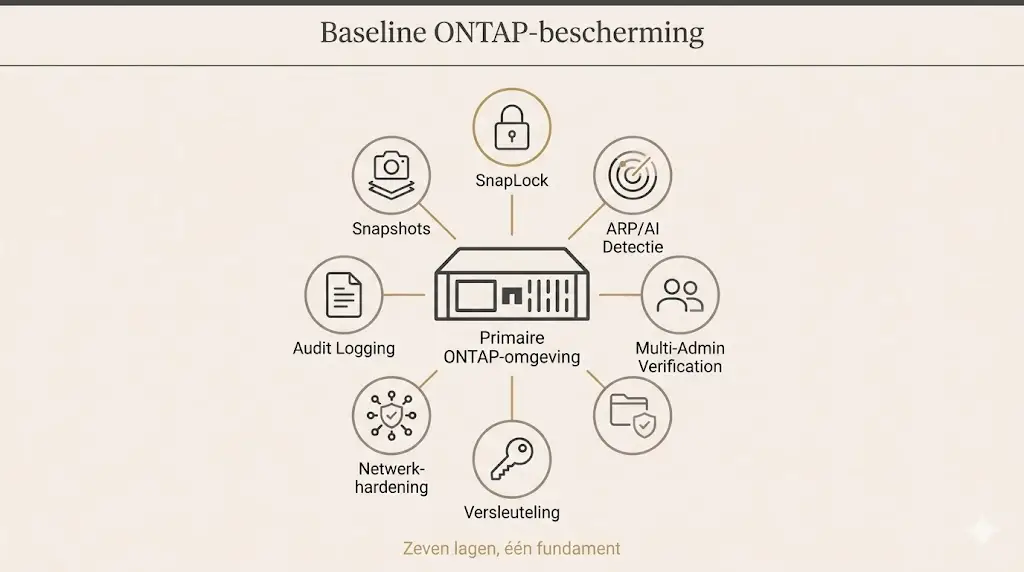
In mijn eerdere blog toonde ik mijn gebruikelijke referentiestructuur: drie lagen die logisch van elkaar gescheiden zijn, met datastromen die slechts in één richting lopen. Mooi op papier, maar een architectuur is pas zo sterk als de laag waarop alles rust. Dus laten we inzoomen op die bewuste laag van je primaire ONTAP-omgeving.
Wat me telkens weer opvalt als ik bij een klant binnenkom, is dat de technologie er meestal al is. ONTAP heeft de meeste beschermingslagen gewoon aan boord. Maar ze staan niet aan. Of ze staan half aan. Of ze zijn ooit door iemand geconfigureerd die inmiddels al twee banen verder is, en niemand durft er nog aan te komen.
Mijn werk is daarom zelden “installeren”. Het is vooral bewust aanzetten, goed inregelen en misschien wel het belangrijkst: daadwerkelijk testen. Hieronder loop ik met je mee door de features die ik standaard activeer en waarom.
Laten we beginnen bij het fundament. Snapshots. Niet sexy, niet vernieuwend, maar als het hier misgaat, helpen de overige maatregelen je nauwelijks.
Toch zie ik het maar al te vaak. Omgevingen waar snapshots of helemaal uitstaan, of draaien op een standaardschema dat al jaren niemand meer heeft bekeken. “Die staan toch goed?” Totdat iemand op een woensdagochtend belt omdat een share leeg is, en dan blijkt dat je drie uur terug kunt, maar de aanval is al sinds vrijdag bezig.
Ik werk daarom altijd met meerdere lagen tegelijk:
Het schema stem ik altijd af op het soort workload. Een fileshare met duizenden kleine wijzigingen vraagt iets anders dan een databasevolume of een VMware-datastore. Eén schema voor alles werkt simpelweg niet. Dat is een belofte aan jezelf dat het ergens een keer pijn gaat doen.
Nog iets wat ik niet vaak genoeg kan zeggen: een snapshot waar je nog nooit iets uit hersteld hebt, is geen snapshot. Het is een aanname. Plan eens per kwartaal een test-restore. Het is een uur werk en je slaapt erna beter.
Goed, je hebt snapshots. Maar wat als een aanvaller beheerrechten heeft en gewoon je snapshots wist voordat hij begint met versleutelen? Dat is precies wat moderne ransomwaregroepen doen. Ze weten dat snapshots hun grootste vijand zijn.
Hier komt immutability om de hoek. Met SnapLock (of Snapshot Locking, afhankelijk van je versie) maak je snapshots echt onveranderbaar. Niet “moeilijk te verwijderen”, maar onmogelijk. Ook voor de senior storagebeheerder met adminrechten. Niet via de CLI, niet via System Manager, niet via de API. Punt.

Mijn aanpak hierbij is altijd:
Dit is geen instelling die je terloops aanvinkt. Het is een keuze met gevolgen. Maar het is wel het verschil tussen “we hebben snapshots” en “we hebben snapshots waar een aanvaller niet bij kan”.
ONTAP kan tegenwoordig zelf detecteren wanneer er iets vreemds gebeurt. ARP gebruikt AI-modellen om I/O-patronen te analyseren: plotselinge bursts van writes, ongebruikelijke encryptiepatronen, volumes die zich ineens heel anders gedragen dan normaal.
Wat ik bij elke klant aanraad:
Dat laatste punt is waar ik de meeste fouten zie. ARP wordt aangezet, vinkje gezet, project afgerond. En daarna ziet niemand de alerts ooit. Een alert die niemand leest is geen bescherming; dat is een logje voor het naoorlogse onderzoek.
Een groot deel van de schade bij een ransomware-incident komt niet van de versleuteling zelf, maar van wat een aanvaller met beheerrechten kan aanrichten. Snapshots wissen. Replicatie uitzetten. Retention policies aanpassen. In een paar commando’s kan iemand jaren aan herstelmogelijkheden vernietigen.
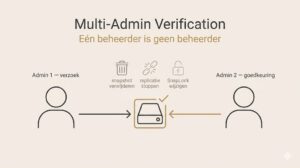
Daarom hoort een strakke rechtenstructuur bij de absolute basis:
MAV is een van die features die mensen aanvankelijk vervelend vinden. “Moet ik nu voor alles iemand bellen?” Nee, alleen voor de dingen waar je echt geen weg meer terug hebt. En je zou verbaasd zijn hoeveel ongelukken, niet eens kwaadwillig, gewoon menselijke fouten op het verkeerde moment, daarmee worden voorkomen.
Een praktische kanttekening: MAV kan in de praktijk schuren met externe tooling die zelf snapshots beheert, zoals SnapCenter, CommVault of AIQUM. Plan vooraf hoe je query-rules inricht om legitieme automation niet vast te laten lopen op approval-requests. Daar valt nog wel een aparte blog over te schrijven.
Versleuteling beschermt je niet direct tegen ransomware. Een aanvaller die jouw data versleutelt, geeft geen ene zier om of die data al door jou versleuteld was. Maar de moderne aanval is allang niet meer alleen versleuteling.
Steeds vaker zie je double extortion: aanvallers stelen je data eerst, versleutelen daarna en dreigen met publicatie als je niet betaalt. Daar helpt versleuteling wel tegen: gestolen data die zij niet kunnen lezen, heeft geen chantagewaarde.
Wat ik standaard activeer:
Op moderne AFF-systemen kost dit nauwelijks performance en bij de meeste compliance-frameworks is het inmiddels een eis. Er is eerlijk gezegd geen goede reden meer om het uit te laten.
Je kunt de mooiste storage-configuratie hebben, maar als je managementinterfaces vanaf elke willekeurige werkplek bereikbaar zijn, doe je het zware werk voor niets. En dit zie ik vaker dan ik wil toegeven.
Mijn baseline:
Klassieke netwerkhygiëne, niets revolutionairs. Maar specifiek voor je storagelaag verdient het extra aandacht. Een gecompromitteerde management-LIF geeft iemand de sleutels tot je hele datafundament. Dat is een avond die je niet wilt meemaken.
Tot slot, en ik beloof je, dit is het minst leuke onderdeel: logging. Zonder logging weet je achteraf simpelweg niet wat er gebeurd is. En zonder centrale logging weet je het alleen op de storage zelf, waar een aanvaller met voldoende rechten ook bij kan.
Wat ik standaard inricht:
Niemand wordt ’s ochtends wakker met zin om door auditlogs te scrollen. Maar op de dag dat het misgaat, is dit het verschil tussen “we weten wat er is gebeurd” en een hoop schouderophalen tegenover de directie.
Als ik bij een nieuwe klant binnenstap, loop ik deze lijst standaard door:

Niets hiervan is op zichzelf revolutionair. Maar samen vormen ze een baseline waar verrassend veel omgevingen niet aan voldoen. En dat is precies het verschil tussen een vervelend incident en een existentiële crisis.
In de volgende blog duik ik dieper in de detectielaag. Hoe werkt automatische ransomware-detectie nu echt? Wat zie je in de praktijk? En hoe voorkom je dat je team alert-moe wordt na de derde valse melding? Ik laat zien hoe ik ARP in productie tune, en welke signalen je echt serieus moet nemen.
Wil je weten waar je omgeving staat ten opzichte van deze baseline? Een korte design-review geeft je binnen een dagdeel een helder beeld van de gaten. Neem gerust contact op via storelinq.nl.
Dit is deel 3 van de blogserie “Ransomware-bestendige NetApp-omgeving bouwen: mijn standaardontwerp als consultant.” Lees deel 1 en deel 2 terug voor de context.